由于某些原因,现在得开发 ovirt-engine 了,简单记录一下 ovirt-enine 的开发环境和调试吧。 PS: ovirt-engine 真不愧是上古老古董项目,是真难用。
安装 ovirt-engine
安装 ovirt-enine 有多种方式,可以在线安装,可以下载完整离线包安装,网上可以搜到一些安装教程,不行就看官网。我平时使用的安装方式无法通用,所以就不在这里说明了(各种组件包括操作系统全部都是固定版本,还有不少安装上的改动,真无法通用)。
在使用 ovirt-enine 提供的 engine-setup 脚本安装时,会提示你安装一堆组件,包括 postgresql、grafana、datawarehouse 等等,全部都同意,都安装上,缺少一些组件不会导致 ovirt-enine 安装失败,但是会有部分功能不可用。
ovirt-engine 简介
在之前,我写过一篇 vdsm源码阅读,而 ovirt-engine 就是 ovirt 这个项目用于和 vdsm 通信的一个平台。vdsm 是安装在物理机上,封装一系列的操作,包括创建虚拟机,创建磁盘,创建网络等等,并暴露接口出来,然后 ovirt-engine 去调用 vdsm 的接口,实现创建虚拟机的操作。架构图参考如下:
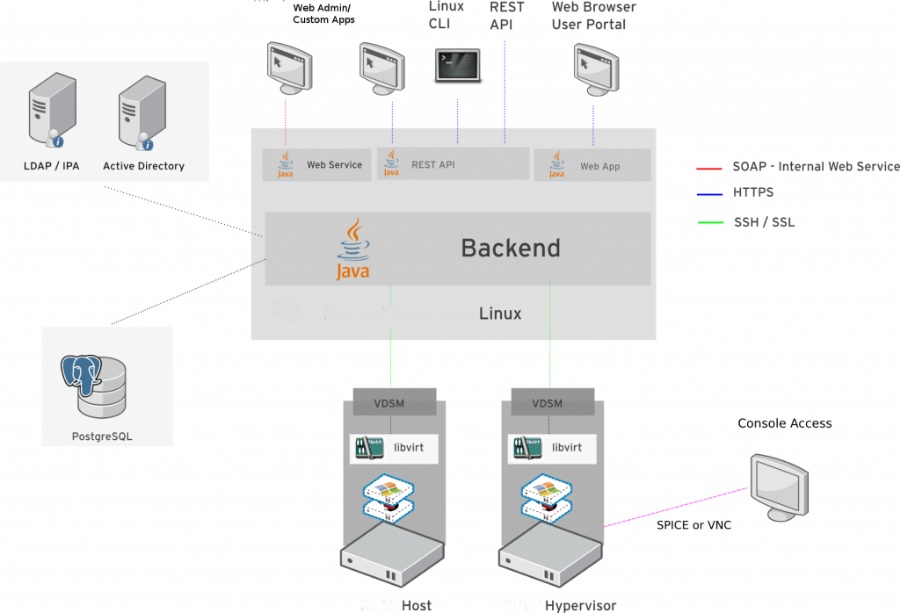
ovirt-engine 是一个 jboss 项目,由于以前没有学过 java 这一坨,在网上找到一篇文章介绍 java 里面一些个概念;Java Bean、EJB、Spring Bean 和一些对象的概念
原来 jboss 已经改名了,现在叫 wildfly(社区版),企业版由红帽提供支持。不得不再感叹一句,这项目是真古老了,之前看 vdsm 代码的时候,基本都是十几年前的提交记录,有个最离谱的,十几年前在注释里写了一句他看不懂这里的参数是干嘛的,我十几年后看到了,我也不知道是干嘛的,也不敢有任何改动。
https://zh.wikipedia.org/wiki/WildFly
https://www.dbi-services.com/blog/jboss-eap-vs-wildfly-whats-the-difference/
验证开发环境
数据库连接
使用 datagrip 或者 dbeaver 等数据库管理工具连接 pg 数据库,记得使用数据库的 engine 用户(该用户是 ovirt-engine 在安装过程中生成的,等安装完成以后,要去 ovirt-engine 的配置文件中找它生成的密码是什么,这里最好不要使用 psql 用户去改 engine 用户的密码),如果使用 psql 用户登录,那么你创建的一些存储过程什么的,由于 owner 变成了 psql,而不是 engine,在打包以后安装部署时会检测,会导致部署失败。
idea 调试
这个项目目前我们只找到一种方式来调试,看这篇文章 ovirt-engine本地开发(四): 调试
使用这种方式来进行调试,有一个地方需要注意:如果你需要打断点,你本地的代码需要和远程的 ovirt-engine 的代码是相同的。也就是说,你只能打个断点,看下断点处的各种变量的数据,如果你要改动的话,需要把代码改了以后,重新打包成 jar 包,上传到远程的 ovirt-engine 去做替换。当然还有另外一种方式可以调试,这是 idea 提供的一个功能,这里我暂时找不到截图了,我记得是要等运行到断点处,然后在 idea 中在断点处使用右键,有一个选项,点开以后,会弹出一个编辑框,可以在那个编辑框中写 java 代码,然后执行,查看效果。
坑
在开发 ovirt-engine 的过程中,有很多坑,比如 ovirt-engine 的用户数据是存在两个数据库里的。。。添加一个用户,需要去修改两个数据库!!!那么当产品提出一个需求,修改一个字段,就要涉及到两个数据库,在 ovirt-engine 中,去使用 aaa-jdbc 的数据库(其中一个,用户登录认证使用)是通过命令行执行的,修改一个字段,就要去通过命令行执行 sql 命令去改数据库的表中的某个字段,但是另外一个数据库封装了 dao,直接调用方法就可以更新。明明只是修改一个字段,页面上看起来应该就是一个很简单的操作,对产品经理来说看起来也应该是一个很简单的功能,放到更现代化的一个项目里,估计几个小时,前后端就都可以对接完了。但是在 ovirt 中不行,除了前面说的要改两个数据库,它前后端也是不分离的。。。这导致前后端的代码必须合并到同一分支才能进行调试,个中曲折,相信有过实际项目开发经验的都能猜到多麻烦,前前后端分离开发时,都还要改来改去,想一想前后端糅合在一起,各种 merge,乱七八糟的 commit,目前还没有找出一个更好的开发方式,以我当前的判断来看,这种开发的模式,如果后面功能越来越多,迟早药丸,起码对开发人员来讲,整个项目的开发会非常乱,工作进度慢导致加班严重,最后跑路。(其实开发这个项目不应该有前后端,应该是所有人都是全栈,一个人负责一个完整的功能项)
还有一个不算坑的坑,ovirt-engine 的管理门户的前后端通信,是走的自己定义的 rpc,基本上都不用担心像使用 json 那样在接口中泄露重要信息,哈哈,也不担心别人搞什么攻击啥的,除非你能把代码注入进来(这么说来,怪不得 java 的项目总是爆出来一些注入的漏洞)。
还有,ovirt-enine 编译挺费内存的,我设置那个参数都直接设置了 32G,默认的编译起来太慢了,等的还久。编译的时候,如无必要,就把那些单元测试去掉算了。(领导要求快速出成果,其它都不重要;单测太浪费时间了,而且会导致为了写单测而改代码逻辑,导致代码变得更复杂)